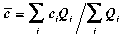 where: c = concentration, Q = flow rate.
where: c = concentration, Q = flow rate.
The data that has been printed in the USGS Open File Report 94-396
(Scribner et al., 1994) have been imported into a database. The
following items have been extracted: sampling-site name, date
of collection (month/day/year), collection time (24-hour), stream-flow
(ft³/s), nitrate plus nitrite as nitrogen (mg/L), atrazine ELISA
(µg/L), and atrazine GC/MS (µg/L). If more than one sample was
taken during one day, the average daily concentration has been
calculated where: c = concentration, Q = flow rate.
The following values have been entered into computer format from the USGS reconnaissance study (USGS Open File Report 93-457, Scribner, 1993): State, site name, date of collection (month/day/year), stream-flow (ft³/s), nitrate plus nitrite as nitrogen (mg/L), atrazine ELISA analyzed in Iowa laboratory (µg/L), atrazine ELISA analyzed in Kansas laboratory (µg/L), and atrazine GC/MS (µg/L). Wherever possible missing values of GC/MS atrazine concentration have been determined from ELISA tests. The following regression equation that relates ELISA atrazine and GC/MS atrazine has been estimated utilizing data published in USGS Open File Report 93-457):
atrazine = -0.0101 + 0.852 ELISA - 0.093 ELISA²
R² = 0.92, 175 observations, Standard Error 0.74 µg/L.
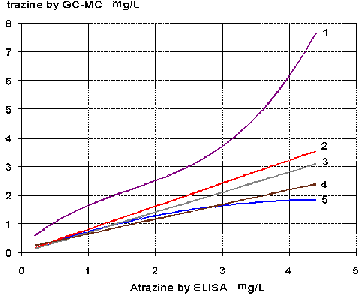
The estimation of the CG/MS atrazine concentrations from the ELISA tests is commonly used in practice. Figure 5.1 compares the estimated in this research relationship with the functions developed by different authors.
Figure 5.1 Relationship between atrazine ELISA concentration
and concentration by GC/MS estimated by a different authors:
Thurman et al. (1992) estimated the following quadratic function (Fig. 5.1, line 1):
atrazine = 0.21 + 2 ELISA - 0.73 ELISA² +0.15 ELISA³, R² = 0.93, n = 127.
It is evident from the Figure 5.1 that there is an error in the published equation.
Goolsby et al. (1993) fitted two regression equations for GC/MS values (Fig. 5.1, line 2 and line 3, respectively), as a function of ELISA values, for samples taken in 1990 and 1991:
1990: atrazine = -0.01 + 0.70 ELISA. R² = 0.94; st. error
of estimate = 0.09 µg/L
1991: atrazine = 0.00 + 0.80 ELISA. R² = 0.78; st. error
of estimate = 0.10 µg/L
In another study, Moody and Goolsby (1993) estimated the following relationship (Fig. 5, line 4):
atrazine = 0.13 + 0.51 ELISA. R² = 0.94, [µg/L]
The streamflow record has been converted from cubic feet per second (ft³/s) into cubic meters per second (m³/s). The two chemical data sets, one from the USGS Open File Report 94-396, and the other from USGS Open File Report 93-457, have been merged and the column containing the site identification number (USGS Station ID) has been added. A simple substitution method (Helsel and Hirsh, 1995) has been applied to values below the reporting limit. For atrazine, 0.025 µg/L replaced a less-then 0.05 µg/L value and for nitrite-nitrate as nitrogen, 0.05 mg/L substituted a less than 0.1 mg/L value. The summary statistics of the atrazine, nitrite/nitrate-nitrogen concentrations and loads, and the corresponding flow rates are presented in Table 5.1.
Table 5.1 Summary statistics of the nitrite plus nitrate and atrazine data sets.
Nitrite/Nitrate data set Atrazine data set
Statistics Flow Load Concentr. Flow Load Conentr.
m³/s g/s g/m³ m³/s mg/s mg/m³
Mean 82.22 249.8907 5.22 101.15 296.62 5.35
St. Error 19.20 16.95 0.14 26.82 39.04 0.37
Median 8.85 28.92 2.91 9.72 11.77 1.00
St. Dev. 694.55 613.18 5.21 819.46 1192.48 11.33
Minimum 0.0028 0.0002 0.05 0.0028 0.0011 0.03
Maximum 20416.56 7603.12 26.00 20416.56 27124.85 116.00
To estimate sampled watershed characteristics a system of distributed watershed parameters has been developed. In this system each cell of the Upper Mississippi-Missouri Basin contains a value that describes a feature of the drainage area upstream of that cell. The 500 m resolution grid, based on the 15 second DEM, is applied to accomplish this task. The following factors justify this approach:
To ensure that the whole region contributes to the outflow, the depressions must be removed. This is performed by GRID procedure fill (Listing 5.1, line 1) which produces a "filled" DEM, mwfil, and a grid that contains indicators of the flow direction, mwfdr. GRID determines one of the eight directions of the flow from the steepest descent: value 1 represents flow in E (east) direction, 2 in SE direction, 4 - S, 8-SW 16 - W, 32 - NW, 64 - N, and 128 in NE direction. No adjustments of the elevations, i.e., "burning in" RF1 streams has been applied to 500 m DEM.
The drainage area upstream of each cell is calculated by multiplying the number of contributing cells, that is calculated by the procedure flowaccumulation(mwfdr), by the area of single cell that is equal to a certain value(in this case, 0.25 km²: Listing 5.1, line 2). The stream network is delineated by assuming that a stream is created from the outflow from area of 50 km² , threshold number of cells (line 3 of Listing 5.1).
Listing 5.1 Creating depressionless DEM, calculating drainage area and delineation of the stream network
Before further calculations are made, the stream network delineated from the DEM is compared with the RF1 map to visually verify the flow system. One major inaccuracy was found: the Wisconsin River, the Mississippi River tributary, has flowed to the Great Lakes. To correct this error the elevation of some cells of the DEM were changed to force the flow in proper direction. Correction of the flow system can also be made by making changes directly to the flow direction grid. The process shown in Listing 5.1 was repeated until satisfactory map of the flow system has been constructed.
This section presents procedures for estimating the grids which each cell contains the following parameters of the upstream drainage area: average slope of the stream network, average exponent of the stream network length, average distance from field to river, and average slope of the watershed.
Slope along the flow path. To estimate the average land slope and the average stream slope the grid that contains values of the slope, measured along the flow path, has to be constructed. Listing 5.2 shows an example of the AML that calculates the slope according to the relation (Hi+1 -Hi)/DL, where Hi+1 is the elevation stored in the cell, e.g., mwfil(1,0) pointed by the flow direction grid mwfdr, Hi is the elevation of the processed cell (mwfil), and DL is the distance; cell width (variable %grd$dx%) or cell diagonal ( variable %diag%), depending on the flow direction value. The full listing of the procedure that calculates the slope along the flow path, is presented in Appendix C8.
Listing 5.2 Average slope of the stream network
Average slope of the stream network. First, the cells that compose the stream network are selected from the grid which contains a description of the direction of flow, mwfdr, - the grid strfdr is created. The number of cells in the upstream stream network is then calculated, using the grid command flowaccumulation. The same command is used to calculate sum of slopes. A grid of average river slope upstream of each cell is obtained by dividing the grid of sum of slopes, slpfacfac, by the grid with the number of cells in the upstream network, strfac. To save disk space, the resulting grid, strslp, is multiplied by 1 000 000 and its values are converted into integer representation. Listing 5.3 shows the GRID dialog which performs this procedure.
Listing 5.3 Average slope of the stream network
Average exponent of the negative stream network length. According to the information presented in Section 4.3.4 the methodology has been simplified by assuming that the mass that enters the surface waters upstream of each cell is equal to one and is uniformly distributed along the river. The reduced formula describing variable ES (Eq. 4.10) has the following form:
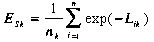 (5.1)
(5.1)
where:
ESk = weighted average of the exponent of negative flow
distance in rivers upstream to the k-th cell (decay),
nk = number of cells that constitute the upstream network
(strfac),
Lik = length of the flow path from the i-th stream
cell to the k-th cell [10² km].
Listing 5.4 shows the GRID dialog of computing parameter ESk. The command flowlength, that determines the downslope distance along the flow path, from each cell to the outlet on the edge of the grid, is used to create the grid, mwflg. The exponent of the negative flow distance, expressed in 100 km, is then calculated. The cells that comprise the stream network are selected and the cumulative value of .the exponent of the negative flow distance is determined.
Since function flowlength calculates the distance from each cell to the outlet on the edge of the grid, not to the watershed outlet, the grid, strexfac, must be divided by the grid, mwexpflg, according to relation:
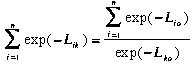 (5.2)
(5.2)
where:
Lik = length of the flow path from the i-th stream
cell to the k-th cell,
Lio = length of the flow path from the i-th stream
cell to the outlet on the edge of the grid (cell o),
Lko = length of the flow path from the watershed outlet
(cell k) to the outlet on the edge of the grid (cell o).
The division by strfac in line 5, Listing 5.4, is introduced to account for the assumption of a unit mass entering river network. The purpose of the operation stated in the last line of Listing 5.4 is to reduce the size of the computer file; integer grids occupy considerably less disk space than the real-number grids (30%-90%).
Listing 5.4 Exponentially decaying flow length
Average length of the flow path from field to the stream. To exclude the cells that represent a stream network from calculations, a grid containing one in the cells that do not belong to the river network, and zero for the stream cells is created in line 1, Listing 5.5. The downslope distance, along the flow path, from each cell that does not represent a stream to all cells that stand for river is calculated in line 2, Listing 5.5. The average value is determined by summation of all distances upstream (line 3, Listing 5.5) and by dividing the resulting grid, lndflfac, by the total number of cells within the given drainage area that are not streams, lndfac (line 5, Listing 5.5).
Listing 5.5 Average distance from field to a stream
Average land slope. Listing 5.6, line 1 shows the command used to create a grid , xlndslp, containing the value of the slope in the cells that do not belong to the stream network, and zero for the stream cells. The average slope, lndslp, is calculated by first, summing all of the upstream values of slope, (line 2, Listing 5.6) and by dividing this cumulative slope grid, slplfac, by the total number of cells within the given drainage area that do not represent streams, lndfac, (line 3, Listing 5.6). The last operation converts the slope grid into an integer format.
Listing 5.6 Average land slope
A grid that represents the USGS sampling sites (watershed outlets) is necessary to extract the parameters of the reconnaissance watersheds from the grids of distributed parameters. This section describes the process used to create such a grid from available data.
The Arc/Info map of 147 sampling sites that are described in USGS Open File Report 93-457 (Scribner et al., 1993) was converted into raster format by the following GRID operation:
sites1 = pointgrid ( sta_recon, station, #, #, 500 )
Unfortunately, four of the nine stations from USGS Open-File report 94-396 (Scribner et al., 1994) are not represented in the sta_recon coverage. Therefore, a coverage of these four sampling sites was constructed from published latitude-longitude coordinates (generate). The attribute table was created (build) and the coordinates of the resulting coverage were changed from geographic projection into Albers projection (project). Finally, this coverage was converted into grid sites2 and merged with grid sites1:
site_all = con ( isnull(sites1) , sites2, sites1)
The site identification numbers, given in attribute table of the sta_recon coverage (Battaglin, 1995) of the three sites, have been changed to site identifiers that are published in USGS Open-File Report 93-457 (Scribner, et al., 1993), as follows:
The location of most of the sampling sites is not completely consistent with the stream network delineated from the 500 m DEM. Figure 5.2 presents an example of a sampling site (Sta-recon map from Battaglin, 1995) that is located neither on the RF1 stream, nor on the stream network that has been delineated from the DEM.
Figure 5.2 Example of the sampling site (from Battaglin 1995) that is located neither on the stream from RF1 nor on the stream delineated from the DEM.
The cells that represent both the sampling site and the watershed outlet must be located on the proper flow path. The following procedure has been developed to adjust the position of gauging stations:
Wherever possible, the locations of watershed outlets that have a difference in drainage area larger then 20% has been adjusted manually using the grid editor included in ArcTools processor. The results have been stored as mwout grid. About 13% of stations had error in drainage area larger than 20%. The discrepancies are due to the relatively low resolution of the DEM used in this analysis and, therefore, small precision of the watershed boundaries. These discrepancies are also due to errors in the estimation of drainage area by the USGS. For example, Kalkoff and Kuzniar (1991) state that the drainage area of sample site 05412100, the Roberts Creek above St. Olaf, Iowa, is equal to 70 mi², whereas Scribner et al. (1993) published a number that is 47% larger (103 mi².)
Listing 5.8 shows the process of extracting watershed parameters from the grids of distributed values and associating them with the site identification number. As a result a VAT is created that contains the following items: mwout (site ID), slps6i2 (stream slope), decs6i2 (decayed flow length), flgl0i2 (flow length from field to stream), and slpl6i2 (land slope).
Listing 5.8 Extracting parameters of the sampled site watersheds
In GRID:
In Arc/Info:
Since the parameters were multiplied by 100000 to convert them to integers, a new info table that contains the recalculated floating point values has been constructed using Arc/Info and ArcView tools. The items and their units in the new table are as follows: station_id, area (km²), decstr (e100km), slpstr (dimensionless), slplnd (dimensionless), and alflgkm (km). The summary of statistics for a selected parameters of sampled watersheds are presented in Table 5.2.
Table 5.2 Selected statistics of watershed parameters determined from DEM. Length of the flow path used to calculate ES is in 100 km
Decayed Stream Land Land
Statistics Area stream Slope Slope length
length
km² ES SS SL LL [km]
Mean 36493 0.59124 0.00168 0.01091 3.34
St. Error 18360 0.01877 0.00007 0.00057 0.04
Median 1685 0.63221 0.00146 0.00871 3.23
Std Dev. 224117 0.22912 0.00091 0.00700 0.50
Minimum 173 0.00353 0.00039 0.00130 2.45
Maximum 2335354 0.91928 0.00702 0.04486 5.51
The mass of agricultural chemical that was applied within each watershed in which the concentrations and flow rate were measured, has been calculated using ARC/Info-GRID. This procedure is presented in Listing 5.9. A detailed description of the process is given below:
Listing 5.9 Chemical application in sampled watersheds
Table 5.3 shows a summary of the statistics of estimated agricultural chemical use in the sampled watersheds. The application rate has been determined by dividing the total agrichemical application by the drainage area.
Table 5.3 Summary statistics of annual application of nitrogen fertilizer and atrazine
Nitrogen fertilizer Atrazine
Statistics Application Appl. rate Application Appl. rate
kg/yr kg/km²/yr kg/yr kg/km²/yr
Mean 43705590 5878.1 219644 26.66
Std Error 7170678 51.7 40274 0.42
Median 10298910 6034.0 48695 25.32
Std. Dev. 259336782 1871.2 1230168 12.74
Minimum 245134 481.6 466 1.00
Maximum 4.79E+09 9481.1 19294461 50.55
The info tables that contain selected watershed features and
annual atrazine and nitrogen-fertilizer application has been merged
with the table that contains measured flow and concentration in
153 sampling sites on the Midwest rivers. Two tables have been
created: atra6 and nitro6. The table, atra6,
contains the following data: state, name (name of the sampling
site), id (station id), area (drainage area in km²), use (total
mass of atrazine use in kg/yr), appl (atrazine application rate
in kg/km²/yr), date (month/day/year of sample collection), day
(day in which sample was collected, 1..365), month (month in which
sample was collected, 1-12), flowm3s (flow rate in m³/s), loadmgs
(atrazine load in g/s), loadgd (atrazine load in g/d), concmgm3
(concentration in mg/m³), decstr (exponent of negative flow length),
declnd (exponent of negative distance from field to stream network),
slpstr (slope of the streams), slplnd (average slope of the land),
alflgkm (average length from field to stream network in km).
The table, nitr6, contains: use (total mass of nitrogen-fertilizer
use in kg/yr), appl (nitrogen-fertilizer application rate in kg/km²/yr),
loadgs (nitrite plus nitrate as nitrogen load in g/s), loadkgd
(nitrate plus nitrite as nitrogen load in kg/d), concgm3 (nitrate
plus nitrite as nitrogen concentration in g/m³)
The other parameters: state, name id, area, date, day, month,
flowm3s, decstr, declnd, slpstr, slplnd, and alflgkm, are similar
to the ones listed for the table atra6.
The statistical program Splus operates only on objects. All data and results of statistical analysis are stored as objects. A table can be stored as an array object or as a frame object. The atra6 and nitr6 data sets has been imported into Splus data object frame:
atra6 _ read.table("atra6" , header=T)
nitr6 _ read.table("nitr6" , header=T)
The stepwise regression has been used to estimate model parameters. The following commands show the Splus session of selecting significant components of the model by the stepwise regression:
alnc.lm _ lm(log(concmgm3) ~ 1, data = atra6) ac1a _ step(alnc.lm, ~ log(appl) + log(flowm3s) + + log(decstr) + slpstr + + log(alflgkm) + log(slplnd) + + month + sin(pi*month/12) + cos(pi*month/12) + + sin(2*pi*month/12) + cos(2*pi*month/12) + + sin(4*pi*month/12) + cos(4*pi*month/12) + + sin(6*pi*month/12) + cos(6*pi*month/12) + + sin(8*pi*month/12) + cos(8*pi*month/12) + + sin(10*pi*month/12) + cos(10*pi*month/12) + + sin(12*pi*month/12) + cos(12*pi*month/12) )
The results of regression analysis are displayed by the Splus command
summary()
summary (ac1a)
Different models has been tested by adding or removing model components. The following line shows removing variable log(appl) from the model ac1a:
ac1a2 _ update(ac1a, . ~ . - log(appl) )
Two diagnostic plots have been used to visually validate the assumption that the residuals are normally distribution:
Despite the possibility of transforming the data within the specification
of the regression model, the new columns in the data frames were
derived from the original data set and tested in new models by
the regression analysis. Below are two examples of creating new
values from existing ones:
nitr6[,"srslpstr"] _ sqrt ( nitr4[,"slpstr"]
)
nitr6[,"etstr"] _ nitr6[,"decstr"] ^ ( 1
/ nitr6[,"srslpstr"] )
The procedure of modeling of agricultural chemical concentration and load in the Iowa River and its tributaries includes:
Selected 1° DEMs are obtained via Internet. Then they are
converted into Arc/Info grids (cell size 100 m) in Albers coordinate
system. The elevations of cells that represent 1:500,000 stream
network (RF1) are modified to enforce the flow to follow the paths
defined by the RF1.
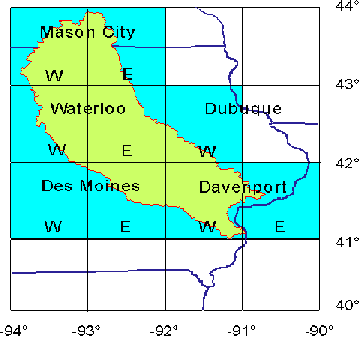
Downloading DEM via Internet. Nine, onedegree quadrangles of DEMs that contain digital elevation data for the region enclosed by meridians: 90° and 94° West (longitude) and by parallels 41° and 44° North (latitude), have been downloaded from the USGS National Geospatial Data Clearinghouse. Figure 5.3 shows the location and the names of the downloaded quadrangles. The files have been uncompressed (UNIX command gunzip), and modified as explained below. The DEM files do not contain record delimiters, thus they should be added by the following UNIX command:
dd if=inputfilename of=outputfilename ibs=4096 cbs=1024 conv=unblock
No direct conversion of the USGS DEM's into Arc/Info GRID format is supported. The Arc command demlattice has been used to convert a DEM in USGS or TAME format into a lattice. The following example shows the conversion of the DEM waterloo_e.dem into Arc lattice us4292lat:
Arc: demlattice waterloo_e.dem us4292lat USGS
After all nine DEMs were converted into lattices, they were merged to construct a single map. For example, the following grid command has been used to merge four lattices:
Grid: crlat1 = merge(us4394lat, us4393lat, us4294lat, us4293lat)
Figure 5.3 1° quadrangles of DEM utilized to subdivide the Iowa-Cedar River basin into modeling units; Map projection: geographic.
The files have been uncompressed (UNIX command gunzip), and modified as explained below. The DEM files do not contain record delimiters, thus they should be added by the following UNIX command:
dd if=inputfilename of=outputfilename ibs=4096 cbs=1024 conv=unblock
No direct conversion of the USGS DEM's into Arc/Info GRID format is supported. The Arc command demlattice has been used to convert a DEM in USGS or TAME format into a lattice. The following example shows the conversion of the DEM waterloo_e.dem into Arc lattice us4292lat:
Arc: demlattice waterloo_e.dem us4292lat USGS
After all nine DEMs were converted into lattices, they were merged to construct a single map. For example, the following grid command has been used to merge four lattices:
Grid: crlat1 = merge(us4394lat, us4393lat, us4294lat, us4293lat)
In Arc/Info, the concepts of lattice and grid are similar, with one important exception. A lattice is a regularly-spaced sample of points representing a surface. Elevation values in a lattice correspond to discrete points. In a grid, the values apply to the entire cell. Although both lattice and grid apply the same data structure, the fact that a lattice represents data at points (has no area) and grid cell has an area, causes differences in how various operators interpret the data contained in lattice and within grid. The further analysis described here, in which the lattices were treated as grids, was not affected by these differences.
Since imported maps are in geographic coordinate system (latitude/longitude) they have been projected into Albers system (project), assuming the cell size of output grid equal to 100 m. Appendix C9 contains a macro that converts a grid into Albers Equal Area coordinates.
Converting river map from vector format into grid representation. The following GRID commands have been applied to specify the cell size and the map extent of the rasterized RF1:
setcell crdem setwindow crdem
The portion of the RF1 map that represents rivers in the Iowa-Cedar River basin has been converted into grid format by applying the linegrid command:
crrf1 = linegrid ( rf1, rf1_id )
The item, rf1-id, from the AAT (arc attribute table) has been used to assign values to the cells that represent rivers. This item has been selected since it allows one to relate the grid VAT table with the RF1.FLOW info table, through one of the following identification fields: CUSEG (hydrologic cataloging unit code and reach segment number) or RR (Reach File ID --an unique identifier for each river reach). The table, RF1.FLOW, contains useful information for hydrologic modeling. For example, it comprises such items as: LFVELlow flow velocity, MFVELmean flow velocity, MNFLOUSGS mean annual flow, and SVTENUSGS 7-10 Year Flow (Lanfear, 1994).
The raster version of RF1 was edited using Arc/Info interactive editing environment, arctools. The lakes were replaced by a single line or, if the region of lake was enclosed, by the series of cells that fill up the enclosed region. The resulting data set was saved under the original grid name, crrf1.
Creating a map of the flow direction and delineation of the stream network. To ensure that the flow paths delineated from the DEM are in line with the RF1 river network, the terrain map has been adjusted. Elevations of all cells that do not represent the real stream network have been raised by 20000 m:
crdem2 = con ( isnull ( crrf1 ), crdem + 20000 , crdem )
The depressions have been removed to ensure that the whole region contributes to the runoff, and the flow direction grid crfdr has been built:
fill crdem2 crfill2 crfdr
Rivers have been delineated under the assumption that the runoff from a drainage area of 25 km² produce a stream. To all cells that have an accumulated number of cells greater than 2500 (= 25 km² with 100 m DEM cells) "flowing" into them, the value one has been assigned:
crfac = flowaccumulation ( crfdr) crstr25 = con ( crfac > 2500 , 1, 0)
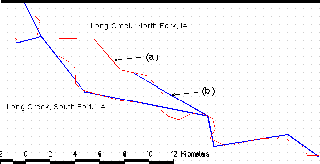
The exercise with conversion of RF1 file into 500 m by 500 m raster format revealed that the cell size of 500 m is too large to represent 1:500000 river network, without ambiguity.
Figure 5.4 Comparison of the stream network delineated from 100 m DEM (a) with the one delineated from 500 m DEM (b).
Some of RF1 reaches are closer to each other than one kilometer, and if converted into grid they are artificially connected. When applied in the procedure described above, these connected rivers cause the GRID command flowdirection to determine a false direction of flow (due to the difference in elevation of watersheds). As a result, the water flowed from one watershed into another through the connected streams that belong to different basins. Figure 5.4 shows low precision of the streams delineated from adjusted 500 m DEM. The same streams but delineated from adjusted 100 m DEM almost perfectly represent the RF1 rivers--this justifies the application of the 100 m DEM in this study.
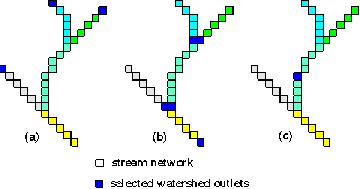
A watershed is explicitly defined by its outlet point. Therefore, to subdivide the basin into elementary watersheds, a set of points -- elementary watershed outlets-- must be specified. Three types of watershed outlets are utilized to subdivide the Iowa-Cedar River basin into units:
Figure 5.5 shows examples of watershed outlets
Figure 5.5 Selected types of the modeling unit outlets
(a) type 1, beginning of the stream network;
(b) type 2, upstream cell of the stream junction;
(c) type 3, USGS gauging station
Beginnings of the delineated stream network (type 1 outlets). As was mentioned in Section 4, the type 1 outlets has been introduced to have more control on the average area of the modeling unit and to determine the flow (and chemical load) conditions at the beginning of the river system. Listing 5.10 shows the Grid dialog that selects appropriate cells. In line 1, the raster stream network crstr25 is divided into "grid zones" crlsl. In Arc/Info GIS a grid zone is comprised from the cells that have the same value. Command streamlink assigns an unique value to each stream reach. In line 2, zonalmin function finds the minimum value in flowaccumulation grid crfac delineated by the zones of crlsl and assigns it to all cells of the reach. Function streamorder (line 3) assigns to each reach a numeric order (Strahler or Schreve). In line 4, the most upstream cell in the first order stream is found by selecting the cell that has the same value in both grids, crlmn and crfac. The value of the selected cells is equal to the value from the grid crlsl increased by 100,000, to indicate the type 1 outlet and thus the type of watershed (source watershed). This number also indicate (after subtracting 100,000) the ID of the downstream unit (intermediate watershed) making the numbering system of the hydrologic structure consistent and efficient.
Listing 5.10 Selecting type 1 watershed outlets.
River junctions (type 2 outlets). The type 2 outlets are determined by selecting the most downstream cell in each stream reach. The selection is made by finding in each "grid zone," defined by grid crsls, a cell that has the maximum value in flowaccumulation grid crfac (Listing 5.11). The last operation shown in Listing 5.11 merges the grid of type 1 outlets with the grid of type 2 outlets.
Listing 5.11 Selecting type 2 watershed outlets.
USGS gauging stations (type 3 outlets) The description of the USGS gauging stations published by the Hydrosphere (Hydrosphere, 1993a) contains latitude and longitude. These coordinates have been used to produce a point coverage of the USGS stations (Listing 5.12). Listing 5.13 shows a part of the file, latlonfl.csv, that contains point coordinates.
Listing 5.12 Creating point coverage of gauging stations from latitude-longitude coordinates
Arc: generate xgsflow Generate: input latlonfl.csv Generate: points Generate: q Arc: build xgsflow point
Listing 5.13 Fragment of the file latlonfl.cvs containing station IDs and coordinates
5448500,-337370,154670 5449000,-337051,154831 5449500,-337056,153936 5451700,-334285,151225 . . .
To make the point coverage compatible with other maps used in this study, it has been projected into Albers system of coordinates as follows (Listing 5.14):
Listing 5.14 Projecting the point coverage of USGS gauging stations from Geographic system into Albers coordinates
Arc: project cover xgsflow gsflow Input Projection geographic units ds Parameters output Projection ALBERS Zunits NO Units METERS Spheroid GRS1980 Xshift 0.0000000000 Yshift 0.0000000000 Parameters 29 30 0.000 /* 1st standard parallel 45 30 0.000 /* 2nd standard parallel -96 0 0.000 /* central meridian 23 0 0.000 /* latitude of projection's origin 0.00000 /* false easting (meters) 0.00000 /* false northing (meters) end
The grid representation of the USGS stations that is compatible with the delineated stream network has been developed using Arc/Info grid editor tools (arctools). The following line combines the grid with the USGS stations crgs with the grid of watershed outlets crlud:
crout = con ( isnull( crlud), crgs, crlud)
Since the gauging station cells may overlap with other cells representing watershed outlets the priority which cell need to be selected in the final map of the modeling units the following statement can be used (grids priority from the highest to the lowest: crlpu, crgs, crlpd):
crout = con( isnull(crlpu) , con( isnull(crgs), crlpd, crgs), crlpu)
The map of modeling units is created by the following Grid statement:
crwsh = watershed (crfdr , crout)
An Arc/Info script has been developed to create the following grids: stream network, watersheds, and watershed outlets. The complete listing of this program, wshgs.aml, is presented in Appendix C1. A first order watershed, and its outlet cell, have an ID number in the range 100000 < ID < 200000. This number is the ID of the first order stream increased by 100000. A watershed that drains through the point at which the gauging station is located assumes the USGS gauging station identification number, 5448500 for example.
To determine the average value of the model parameters for the drainage area upstream of a given point, the sum of values for all upstream modeling units must be calculated. All these units can be identified if the position of each unit on the flow path is known. The Arc/Info script nextwsh.aml creates an info file with two items that store the modeling unit ID number and the ID number of the next unit on the flow path (downstream unit). The listing of the macro nextwsh.aml is shown in Appendix C2. The major part of this AML assigns to the cell that corresponds to the watershed outlet crout a value from the cell, located in watershed grid crwsh, that is pointed by the flow direction crfdr. In line 1, Listing 5.15, a value zero is assigned to all cells that have nodata (xcrwsh). This step is necessary to ensure that the next watershed to the last unit on the flow path is indicated by the ID equal zero (no downstream units). Lines 2-9 create a grid crnxt similar to the grid of watershed outlets crout but with ID of the downstream unit.
Listing 5.15 Identification of the downstream watershed ID
Two problems occurred when the grid of modeling units was converted into vector format:
To solve the problems mentioned above, all zones of smaller area than one km² have been incorporated into neighboring units. The GRID nibble command replaces areas in a grid corresponding to a mask with the values of the nearest neighbors:
aaa = crwsh.count aaa2 = con (aaa > 100 , 1 ) crwsh2 = nibble(crwsh, aaa2, DATAONLY )
The nibble command has also been used to remove the upstream portion of the unit composed of two parts connected only by the cell corner.
The removal of small drainage areas introduced discontinuity of the flow system. A program has been written in C language to determine the new relation between modeling units. The C code of the program newnx.c is listed in Appendix A1. This procedure requires two text (ASCII) files. In first file, each line contains two numbers separated by a comma: unit_id and the downstream unit_id, for the original set of modeling units. The second file contains only the list of unit_id --identification numbers of units that remained from the original set after some of them have been removed. Program newnx creates an ASCII file in which it stores updated information about system connectivity. In each line, the following numbers are written, separated by a comma: unit_id, downstream unit_id, and numeric order of the unit in the flow system.
By assigning a numeric order to each unit, the further calculations are more efficient. The method of stream numbering is as follows: all exterior units, i.e., the most upstream units are assigned an order 1. The order of each interior unit is calculated as the maximum order of the upstream units increased by one.
The advantage of the program written in C over the procedure written in Arc/Info macro language or in ArcView script language Avenue, is that the C program, after minor changes, can be used by both Arc/Info and ArcView, whereas program written in AML can be executed only from Arc/Info, and script written in Avenue language can only be run from ArcView. The additional advantage of writing more complex procedures in such languages as FORTRAN or C is that the time of execution is very fast. The time gain is on the order 1000, i.e., the computational hours can be reduced to seconds.
Figure 5.6 The Iowa-Cedar River basin subdivided into unit drainage areas.
The following assignment creates the final map of the modeling units in vector format (weed tolerance = 180 m):
crwsd = gridpoly ( crwsh3 , 180 )
The map of subdivision of the Iowa -Cedar River basin into 1032 modeling units is presented in Figure 5.6.
The time series of the average monthly flow rate and the average precipitation depth for 38 USGS gauging stations and 86 weather stations, for the time period from January 1940 to September of 1992, have been extracted from the Hydrosphere CD-ROMs (Hydrosphere, 1993 a, b ) and stored in a worksheet format.
The units of measurements have been changed: cubic feet per second (cfs) into cubic meter per second (m³/s) (flow) and inch per day into centimeter per day (cm/d) (precipitation). For each parameter two sets of ASCII, comma delimited files have been created. One set contains identification numbers of observation stations and respective longitude and latitude, expressed in decimal seconds. The other set of files comprise the station ID number and the time series of flow or precipitation.
The point coverage of 86 precipitation stations has been created from the ASCII files and projected into Albers Equal Area system of coordinates. This procedure is identical to the one described in a previous section for generation of point coverage of USGS stations.
The ASCII files that contain flow and precipitation measurements have been converted into Arc/Info INFO files and linked with the appropriate maps.
The method of spatial redistribution of measured flow rate utilizes the precipitation depth as a weighting factor. Therefore, the monthly average precipitation depth must be calculated for each modeling unit. The example of the GRID dialog which calculates a raster map of the average precipitation depth, in modeling each modeling unit for May 1990 is shown in Listing 5.12. The grid of distributed precipitation depth has been created directly from the weather station map. The inverse distance weighting procedure iwd has been applied. To make the calculations shorter and to save the disk space, 100 times larger cells (width = 1000 m, area =1 km²) than those used for the stream and modeling unit delineation have been assumed (setcell 1000). The average values for each modeling unit has been determined by the zonalmean function. To create an attribute table, the cell values must be represented as integers. In line 7 of listing 5.16, the grid, xxx1, that contains zonally averaged precipitation depth is first multiplied by 10000 to preserve decimal part and then converted into integer format. The command combine has been used to create a table in which the modeling unit identification number (stored in grid crwsd) is related to the estimated average precipitation depth (stored in grid xxx2).
Listing 5.16 Estimation of the average precipitation depth in modeling units
Since the procedure described above must be executed for each month, it has been included into AML's DO feature that repeats calculations for each month of the specified time period,. i.e., from month %fm% of the year %fy% to month %tm% of the year %ty%. An example of the &DO block is presented in Listing 5.17
Listing 5.17 Application of the &DO command to repeat action for each month of the selected time period
Appendix C3 contains the code of the Arc/Info macro RAININFO.AML. This program calculates average values for specified zones and then writes them into an INFO file. The user must specify the period for which the estimations have to be made, the point coverage that holds the time series, and the grid that divides the region into zones. The output of the macro is the Arc/Info INFO file that contains for each zone the ID number and the series of computed zonal averages.
In the approach presented above, only stations that have complete time series, i.e., stations that have no missing values, have been applied. The macro SELDATA.AML that is included in Appendix C6 selects stations that have a complete record in specified time interval.
To include all available measurements of precipitation depth, another approach has been tested. The stations that have data for the processing month have been used, unlike in the method discussed above in which only the stations that have data for all months of the specified time period have been utilized. For each month, station selection is performed (Arc/Info command reselect) and then the grids of spatial distribution of the precipitation depth are calculated (IDW procedure). This task is performed by the macro RAINMAP.AML (attached in Appendix C4). The results were slightly different, but since the zonal averages were calculated later, the differences were insignificant. Listing 5.18 shows the exemplary procedure that selects all stations from the database (coverage prcmap) that have a complete record in June, 1966 (point coverage xxx), and then it creates the grid of precipitation (pm196606) by the inverse distance-squared method:
Listing 5.18 Example of the AML that selects precipitation stations that have a complete record in June, 1996 and creates the grid of precipitation depth (adopted from RAINMAP.AML)
Three approaches have been made to incorporate the procedure described in Section 4.5 into GIS. Coding has been made in:
For the first two approaches, the calculations of the flow rate for a single month took hours, whereas the program written in C language redistributed the flow record in a few seconds. Therefore a method that uses the Arc/Info Tables to prepare the data and then utilizes the C program to calculate the flow rate in modeling units has been developed. It is explained here for a single month: March 1990. The full Arc/Info macro--fd4y.aml--is presented in Appendix C7. The C program--fd4y.c--is listed in Appendix A2. The fd4y program requires two input files and it stores the results in one output file. In lines 2 and 3 of Listing 5.19, the Arc/Info processor, Tables, creates the first input file xxxgsin in which the following items of the point attribute table gsfl28.pat are stored:
The second input table, xxxunin, is prepared in lines 4 and 5. The following items are unloaded from the polygon attribute table unprec.pat:
The program fd4y is executed in line 6. Since UNIX is a multitasking system, the AML must wait until fd4y finishes calculations. Lines 7 to 10 contain the loop in which AML checks if fd4y program created output file xxxunout. In lines 11 to 14, the temporary INFO file m199003.dat is created in which the results of the fd4y calculations are stored (line 15). Then, the estimated flow rate is attached to the Arc/Info database file unflow.pat (line 17) and the temporary file m199003.dat is deleted (line 18). In the complete version of this procedure (fd4y.aml), the process described here is repeated for all months from the specified time period. Figure 5.7 presents an example of estimated runoff that occurred in June 1990.
Listing 5.19 Example of the Arc/Info macro that prepares data and estimates the flow rate in modeling units (adopted from fd4y.aml, Appendix C7)
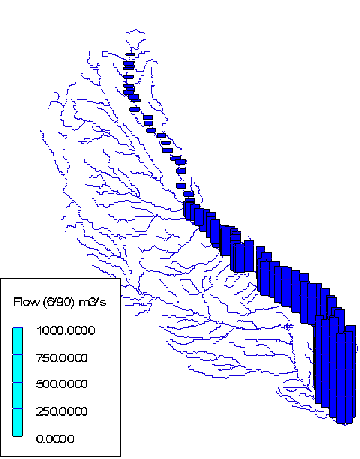
Figure 5.7 Runoff (flow in rivers) that occurred in June 1990 in the Iowa-Cedar River watershed.
The flow rate at the outlet of each modeling unit has been estimated by the procedure described in Section 5.4.7. The characteristic of the drainage area that is upstream of each modeling unit outlet, has been extracted from the distributed system of watershed parameters , which were determined according to the methodology discussed in Section 5.2.2.
The computer version of the agrichemical transport model is completely constructed within the GIS software ArcView. The modular structure has been utilized. Such a structure not only makes the model simple and easy to understand, but also it allows improvement of the model or addition of new blocs without changing the model's core components. The program execution is supported by the customized graphical user interface (GUI). Tools that enhance the graphical representation of the results are developed. The model contains procedures that support the hydrologic modeling process.
Modular structure. The ArcView application is divided into four projects (a project is a collection of associated documents: views, tables, layouts, charts, and scripts). Each project is designed to perform a different task. Four buttons that allow user switching between projects have been placed in the PushButton Bar (the avenue scripts assigned to each button are listed in Appendix B1):
 Runs the "model" project. This project is designed
to prepare entry data for the agrichemical transport model as
well as to calculate concentrations and loads.
Runs the "model" project. This project is designed
to prepare entry data for the agrichemical transport model as
well as to calculate concentrations and loads.
 Runs the "results" project which is designed to display
the results: maps of agrichemical concentration and load.
Runs the "results" project which is designed to display
the results: maps of agrichemical concentration and load.
 Executes project "flwprc". Visualization of the flow
record for a selected modeling unit.
Executes project "flwprc". Visualization of the flow
record for a selected modeling unit.
 Project "tools" contains the fundamental tools for
hydrologic modeling.
Project "tools" contains the fundamental tools for
hydrologic modeling.
The project "model" is the main component of the ArcView application. Projects "results", "flwprc", and "tools" are supporting modules. The scripts associated with the project "model" are listed in Appendix B2. The scripts used by the projects "results", "flwprc", and "tools" are presented in Appendix B3, Appendix B4, and Appendix B5, respectively.
Graphical User Interface. The agrichemical transport model is navigated through a set of buttons that, when pressed, execute particular model components. The data entry and the data selection is maintained by a set of windows. Figure 5.8 presents an example of a window that supports selection of the agrichemical application rate to be used for concentration estimation.
Figure 5.8 Example of the Graphical User Interface: a window for the selection of the agrichemical application rate in selected counties.
Presentation Tools. These tools are developed to enhance the presentation of the data and the model results on a map. Figure 5.9 shows examples of the application of the presentation tools.
Figure 5.9 Atrazine concentrations along the Cedar River estimated for 1990 (a) and flow rate along the Cedar River in June 1990 (b).
Hydrologic modeling tools. The hydrologic modeling is supported by scripts that perform the following tasks:
When opened, the project "Model" displays the following maps:
Five buttons are designed to select different activities:
 Edit Application. This button displays dialog boxes that allow
the user to specify the agrichemical application rate. If the
view-window "Application Rate" is active, the application
in either all, or selected counties can be specified. Additionally,
the application rate of nitrogen fertilizers estimated for 1989,
1990, and 1991, and application rate of atrazine estimated for
1989 can be selected. If the view-window "Modeling units"
is active, the application rate in each modeling unit can be modified.
Edit Application. This button displays dialog boxes that allow
the user to specify the agrichemical application rate. If the
view-window "Application Rate" is active, the application
in either all, or selected counties can be specified. Additionally,
the application rate of nitrogen fertilizers estimated for 1989,
1990, and 1991, and application rate of atrazine estimated for
1989 can be selected. If the view-window "Modeling units"
is active, the application rate in each modeling unit can be modified.
 Edit Cumulative Flow Rate. This button shows dialog boxes for
selecting the flow record (by selecting a year) that will be used
for calculations and for adjusting the selected values. For example,
all data can be multiplied by a factor that represents extreme
conditions. The adjustment may be performed for all months of
the specified year or for each individual month.
Edit Cumulative Flow Rate. This button shows dialog boxes for
selecting the flow record (by selecting a year) that will be used
for calculations and for adjusting the selected values. For example,
all data can be multiplied by a factor that represents extreme
conditions. The adjustment may be performed for all months of
the specified year or for each individual month.
 Select Year. This button allows the user to specify a year for
a model that has a trend component. There is no trend in current
model.
Select Year. This button allows the user to specify a year for
a model that has a trend component. There is no trend in current
model.
 Select Month. The dialog box displayed by this button specifies
if the calculations will be performed for all or only selected
months of a year.
Select Month. The dialog box displayed by this button specifies
if the calculations will be performed for all or only selected
months of a year.
 Run. Executes the script that performs the calculations.
Run. Executes the script that performs the calculations.
 First Order Reaction. Calculates concentrations and loads assuming
exponential decrease of the agricultural constituent along the
flow path.
First Order Reaction. Calculates concentrations and loads assuming
exponential decrease of the agricultural constituent along the
flow path.
The following coverages and data files constitute the core database of the model:
1) Coverage cruse--map of 47 counties that are within the Iowa-Cedar River basin. Table 5.5 presents the items of the cruse's PAT.
Table 5.5 Polygon Attribute Table of the cruse coverage
Field (Item) Description
Fips county FIPS code St state Cntyname county name N89kgkm2, estimated average nitrogen fertilizer application N90kgkm2, rate for the years 1989, 1990, and 1991, N91kgkm2 respectively [kg/km²] A89kgkm2 estimated average atrazine application rate for 1989 [kg/km²] Temp field reserved for storage of results of partial calculations Use application rate selected for the estimation of concentrations and loads
2) Coverage crwsd--map of 1033 modeling units. Table 5.6 lists the items of the attribute table.
Table 5.6 Polygon Attribute Table of the crwsd coverage
Field (Item) Description
Unit_id ID of the modeling unit Gswsh ID of the USGS gauging station downstream of the modeling unit Unit_nx ID of the next unit on the flow path (downstream unit ID) Order a number that specifies location of the unit on the flow path Areakm2 area of the unit [km²] Careakm2 drainage area upstream of the unit outlet [km²] Alndslp average land slope of unit drainage area Alndlgkm average length on the flow path from the land to the stream network [km] Chemuse Agrichemical application rate in the unit [kg/yr/km²] Cchemuse average agrichemical application rate over the unit drainage area [kg/yr/km²] Travtime Agrichemical travel time across the unit [d] (no data available) Losscoef Overall loss coefficient in the unit [1/d] (no data available) Expofact Export factor, fraction of the applied agricultural chemical in the unit that enters the surface water (no data available) Flow01..Flow12 monthly flow rate that flows through the unit outlet [m³/s] Conc01..Conc12 concentration at the unit outlet (atrazine [mg/m³], nitrate plus nitrite as nitrogen [g/m³]) Load01..Load12 chemical load (flow * concentration, atrazine [mg/s], nitrate plus nitrite as nitrogen [g/s])
3) File Linkuse.dbf--description of the link between counties and modeling units (1517 records). Three items describe the link: Fips (county FIPS code), Unit_id (ID number of the modeling unit or part of the modeling unit that is located in the county described by the FIPS code), and Area_km2 (area of the unit or part of the unit that is located in the county specified by the FIPS code [km²]).
4) Coverage Unflow -- map of 1033 modeling units. The PAT file contains item Unit_id, and items Qm196001...Qm199209, that store the cumulative flow rate estimated for the period from January 1960 to September 1992.
5) Coverage Unprec -- map of 1033 modeling units. The PAT file contains item Unit_id, and items Pm195001...Pm199306, that store the average precipitation depth estimated for the period from January 1950 to June 1993.
6) File Model2.dbf -- model specification. Table 5.7 shows the fields of this file.
Table 5.7 Fields of the file model.dbf (model specification)
Field Description
Year a year that is used to estimate the trend coefficient; Ftrend mathematical description of the trend. Current version of the model assumes no trend, i.e. the trend is described by the following equation: 1.00+(0.0000*Year) Trendcf trend coefficient which is calculated according to the information stored in items Year and Ftrend Si01..Si12 seasonal index Model model name, e.g. Nitrate01, Atrazine01, Atrazine02 Sel contains 1 if the model is selected for calculations, 0 otherwise Equation equation for estimation of agrichemical concentrations. Three models are available, 1) nitrate plus nitrite as nitrogen [g/m³]: 0.000143208*(U^1.3814)*(A^(-0.5556))*(Q^0.4240)*(LL^0.9522)*TR*SI 2) for atrazine [g/m³]: 0.0001265546*(U^0.8323)*(SL^0.3591)*(Q^0.0940)*(LL^0.9208)*TR*SI 3) for atrazine, same as (2) but different output units [mg/m³] 0.1265546*(U^0.8323)*(SL^0.3591)*(Q^0.0940)*(LL^0.9208)*TR*SI where: U = application rate, A = drainage area, Q = flow rate, LL = average overland flow length, SL = land slope, TR = trend coefficient, and SI = seasonal index. Comments comments and model description
The ArcView script equat6 (Appendix B2) calculates concentrations and loads. This script first selects the record that contains the value of item [Sel] equal to 1. Then equat6 extracts the value from the item [Year], retrieves the equation that describes the trend from the item [Ftrend], calculates the trend coefficient, and stores it in the item [Trendcf].
In the next step, the script extracts the equation from the item [Equation] and replaces the symbolic names U, A, LS, LL, and Q with the corresponding item names [Cchemuse], [Careakm2g], [Alndslp], [Alndlgkm], and one of the item [Qm01]...[Qm12]. The symbolic name TR is replaced by the value stored in the item [Trendcf] and the name SI is replaced by the value from one of the items [Si01]...[Si12]. The concentrations are calculated for each month of the year by the Avenue request calculate and the results are stored in the items [Conc01]..[Conc12]. The loads are estimated by multiplication of the flows and concentrations. The products are stored in the items [Load01]...[Load12].
Calculations of the agrichemical concentration in surface waters, according to the first order process, are performed by the script decay1. This Avenue program has been written to utilize the results of the CEEPES (Comprehensive Environmental Economic Policy Evaluation System) modeling program developed by Iowa State University's Center for Agricultural and Rural Development, CARD (Bouzaher and Monale, 1993). The results of estimations of agrichemical runoff from the field in the NRI (National Resources Inventory) have been delivered from CARD by Gasman (1995), but since the detailed information about location of the NRI points is confidential, CARD results could not be used in this research.
This project reserves the space for preparing the maps of estimated
agrichemical concentration and load in surface water. Three scripts,
executed from the button bar, , draw the bar charts of
the monthly average chemical concentration, chemical load and
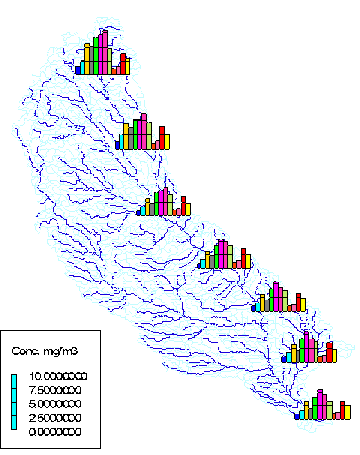
flow rate, respectively. Figure 5.10 presents the agrichemical
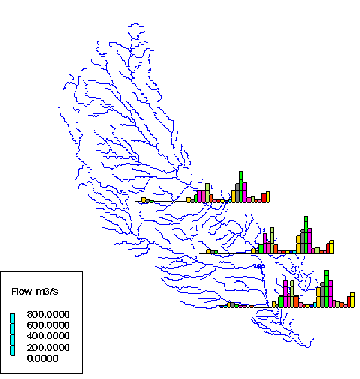
model results of the estimation atrazine concentrations in 1990
in the form of bar charts located along the Iowa River and the
Cedar River.
, draw the bar charts of
the monthly average chemical concentration, chemical load and
flow rate, respectively. Figure 5.10 presents the agrichemical
model results of the estimation atrazine concentrations in 1990
in the form of bar charts located along the Iowa River and the
Cedar River.
Figure 5.10 "Bar chart" map of the atrazine concentrations estimated for 1990 -- an example map created within the ArcView project "Results"
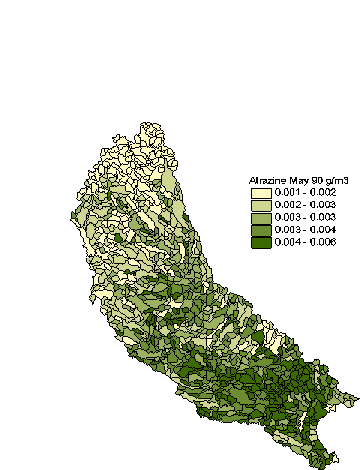
The results of the calculations can be presented on the map of modeling units. Figure 5.11 shows an example of atrazine concentrations in streams for May 1990.
Figure 5.11 Atrazine concentrations in the Cedar River basin estimated for May 1990 -- a map created within the ArcView project "Results"
The bar charts that represent the monthly flow rate and the average
precipitation depth for a selected time period can be drawn at
the center of selected modeling units ( draws charts of the flow
rate and
draws charts of the flow
rate and  draws charts of the precipitation depth). The script
associated with the button
draws charts of the precipitation depth). The script
associated with the button  displays all recorded flow rate (monthly
values from January 1960 to December 1992) for a specified modeling
unit. Since charts of monthly flow rate for multiple year periods
can be drawn, the wet or dry years can be easily identified. Figure
5.12 presents the monthly flow for years from 1989 to 1991.
displays all recorded flow rate (monthly
values from January 1960 to December 1992) for a specified modeling
unit. Since charts of monthly flow rate for multiple year periods
can be drawn, the wet or dry years can be easily identified. Figure
5.12 presents the monthly flow for years from 1989 to 1991.
Figure 5.12 Monthly flow rate in the lower Cedar River in 1989-1991. Example of visual tools of ArcViev project "Flwprc" for hydrologic analysis.
The following tools have been created to support the model of agrichemicals in surface waters (Avenue scripts are included in Appendix B5):
 Determines the unit/stream order in the flow system (Avenue
script order6);
Determines the unit/stream order in the flow system (Avenue
script order6);
 Calculates weighted average for each modeling unit total drainage
area (script upavg2);
Calculates weighted average for each modeling unit total drainage
area (script upavg2);
 Accumulates values going along the flow path (script cumul2);
and
Accumulates values going along the flow path (script cumul2);
and
 Calculates the difference between the unit inputs and the unit
output (script decom2).
Calculates the difference between the unit inputs and the unit
output (script decom2).